
The NVMe revolution – how we deployed NVMe as a storage solution to optimize performance and overheads (UPDATED)

Uptime and performance is what customers care most about when searching for a reliable web hosting provider.
To achieve this, a web hosting provider needs to find a good balance between fast performance, security, redundancy, and low cost for their platform.
This is where a cost-effective data storage solution – a key digital services component for preserving business-critical information, kicks in.
However, storage could be very expensive, especially if based on enterprise solutions.
For most major, high-margin companies, deploying a working commercial solution would not pose a problem.
Surely, if you go with commercial SDS you should have a great solution in place. However, the costs would be tоo high for smaller companies to keep up with.
This is why small and medium-sized business providers are looking for more affordable solutions that could offer a decent balance between performance, redundancy, and price.
In this post we’ll discuss our experience with some of the mainstream storage solutions in search of the most cost-effective storage system, and how we went for one that is perfectly fine-tuned to our needs.
***
Over the years, we’ve always striven to maintain a storage system that enables us to offer an excellent and fast service to our customers.
As a low-margin provider, the sought-after balance between performance and cost motivated us to experiment with different solutions over the years, both mainstream and custom-built ones, which offer the bells and whistles of enterprise solutions for less money.
Software-defined Storage (SDS)
Some years ago, we started with Software-defined storage (SDS) – a proven mainstream commercial solution.
We tried buying SDS setups from various companies. However, the software license fees were mind-blowing. That combined with the expensive hardware made that solution ineffective for us.
For instance, a regular SDS solution would cost between $500 and $1500 per usable TB per year for software license and support.
For 100 TB of data, that would mean $50 000 to $150 000 per year for storage without the hardware costs!
Well, at least this solution does not require additional staff to manage which, however, was not a solid argument for us to stay with that setup.
That’s why we started investing in other, more cost-effective options which finally brought us to using Ceph for a period of 3+ years.
Ceph storage
Working with Ceph as a storage system is quite simple which is why it is chosen by а large number of web hosting and IT solutions providers today.
However, there are a few downsides to using Ceph, which are hard to ignore.
So here they are; this is what we gleaned during our hands-on experience with the system:
- maintenance vulnerability; even with 3 data replicas, if you take a node down for maintenance and lose one drive from the remaining nodes, your data will be at risk. The best thing you can do in this case is stop all IO operations to the pool so as to avoid data loss. This will lead to hours of downtime until the first node is returned and the data re-arranged to have at least 2 copies of data in place;
- hidden vulnerabilities; you will be surprised but when you search for Ceph examples and use cases, it will be difficult to find a problematic Ceph setup report; The reality, however, is that there are a huge number of issues that occur with various Ceph setups. In our practice, we came across a few hidden issues caused by various bugs blocking data on some OSDs, etc., which led to slow performance or even downtime thus compromising service reliability.
- latency; you will hear that the bigger a cluster is, the faster it performs. Yes, that is true, however, it is not linear growth. We’ll illustrate that with an example: If we have a Ceph setup consisting of 3 nodes, each with 10 SATA SSDs (size 3.84 TB), with replica 3, we’ll have available а total of approximately 34 TB of usable data. On a 10 Gbit spf+ network, this will give us a speed capacity of about 30 000 IOPS. That does not sound like a big figure, does it? Besides, after ¾ of that speed limit of the cluster is reached, the latency spikes so high that it becomes unreasonable to push for the remaining ¼ of the cluster speed. So, you would suppose that if you put 9 nodes, you would be able to get 90 000 IOPs, right? Well, that’s not the case with Ceph. You might get 40-45 k or even reach up to 50 000 IOPS, but not even close to 90 000 IOPs. Thus, 40% to 50% of the IOPS will be lost. The only way for you to get 90 000 IOPS is to set up 3 separate clusters. Still not much for 90 SSDs, right?
- inconsistent latency on VMs; using the Ceph cluster has turned out to bring about +100% to +2000% higher latency compared to direct-attached storage, depending on the cluster load. As with the above example, when you reach a certain level of IOPS load, the latency spikes causing exponential problems for all clients using the Ceph cluster.
- extra expertise needed; one of the biggest disadvantages of Ceph is that it requires dedicated, well-trained stаff to manage the cluster – specialists who know the game (you can’t really play and experiment a lot with your customers’ data). Depending on the project, you may need to have 1 or more people dedicated to cluster supervision or hire an external company to do that for you, which would incur extra costs.
As for the Ceph storage cost, the prices vary between $600 and $1000 per TB, with hardware (for replica x3) included. You would need to add the support expenses mentioned above to that.
So, to sum up our experience with Ceph – it is great for a home setup or for small companies whose data does not depend on 24/7/365 availability, but still want the bells and whistles of enterprise solutions for less money.
Direct-attached Storage (DAS)
Apart from the distributed storage solutions mentioned so far, we’ve also experimented with direct attached storage (DAS)/local storage.
Here is our takeaway from working with direct storage.
Starting with the positive aspects, direct storage offers a couple of positives such as:
- ultimate performance; nothing is faster than direct storage;
- simplicity of use; unlike Ceph, no specially trained staff are required to oversee the system; almost everyone of your Linux administrators could do the job.
Now let’s move on to the deficiencies we detected working with direct storage:
- very limited hardware redundancy; you can ensure maximum redundancy by adding +1 or +2 drives as spare, or by using RAID 1/5 (you will still be OK in the event of a drive loss) or RAID 6/7 (data will remain intact if 2 or 3 drives are lost). However, there is no way to ensure the redundancy of the hypervisor (the hardware node running the VM’s) which is a major drawback regarding the stability a hosting provider wants to achieve.
- non-reliable failover; in case of hardware failure or maintenance drives must be manually moved to another healthy server; this inevitably causes downtime and is fully dependent on the staff in the data center in which case the downtime could last hours, even days;
ZFS-related storage with JBOD
In our pursuit of the best storage solution for our platform, we also experimented with ZFS – a time-proven file system.

One way to implement ZFS is to directly rent it as SDS which may be quite expensive, even if you find the best software deal (Nexenta is probably the most expensive vendor followed by OSNexus, etc.).
Alternatively, you could build a ZFS system using FreeBSD or ZFS for Linux, which, however, requires a dedicated and experienced staff with in-depth knowledge of ZFS management.
We took a more cost-effective approach and decided to create a custom ZFS solution based on SAS SSDs, JBOD and non-commercial software (meaning no Nexenta, OSNexus, etc.).
JBOD stands for “Just a Bunch of Disks” and it is used mostly for ZFS-related storage based on SAS HDDs/SSDs.
JBODs were very popular until recently, when people started to look around for more flexible solutions.
So did we, as the ZFS setup we had worked on back then appeared to be too tricky to maintain.
That was largely due to the ISCSI storage protocol, which turned out to be a bit risky to use for our specific needs.
In our case, when used for a large number of VM’s on HyperVisors, the ISCSI protocol did not act as expected, which could potentially lead to data corruption on the ZFS server.
And once you are faced with data corruption as a provider, you are screwed …
Our custom, in-between solution (flash storage w/ JBOF)
Learning from our experience with various storage systems and setups on the market, we grew more confident in what our storage system should be like.
We now knew what to seek for – a solution that combines the great redundancy of SDS systems with the high performance/low latency and ease of management of DAS setups.
Basically, we wanted to come up with a much simpler solution that does not require specific technical expertise to manage it.
It is still a matter of data management so you would still want someone very responsible to work with the system.
However, you’d not need to invest heavily in a system that requires expensive, complex training or some special skills to operate it.
So finally, after years of searching and experimenting, we found it.
We found the hardware setup that would allow us to build our own, fully redundant, high-performаnce and easy-to-manage storage system.
The following is the hardware configuration we finally went for:
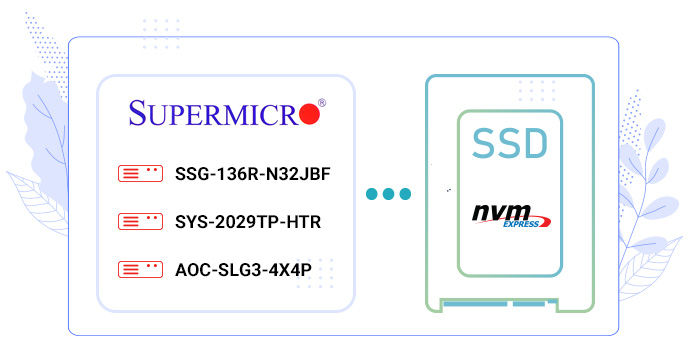
It is quite a simple and cost-effective setup and its only limitation is that it is locked to a certain hardware vendor – in our case it is SuperMicro.
Thus, the setup requires Intel CPU’s, SuperMicro TwinPro/BigTwin/Ultra/WIO servers and SuperMicro JBOF.
And since this vendor supports only Linux and Windows, the choice of OS’s you could work with is limited.
On the other hand, this specific setup gives you the flexibility to run various file systems.
This setup led us to a turning point – we evolved from using SAS SSDs with JBOD to the much more advanced flash storage solution – NVMe SSDs on JBOF.
In our blog, we’ve already touched upon NVMe and the performance revolution it has brought to the market.
So what is JBOF, which underlines the new storage system setup using NVMe SSDs, about?
Recently, many companies have announced their transition to offering JBOF for NVMe.
The first time we heard about JBOF we were really excited about the idea of JBOF being JBOD for NVMe.
However, that was not the case. Most of the JBOFs offered nowadays are not what you would call a passive solution that you can hook up to another server and get working like JBOD.
They are actually regular servers, supporting NVMe and they provide access to the SSDs via NVMeOF.
NVMeOF stands for NVMe Over Fabrics and it is a protocol that provides remote access of other servers to the NVMe SSD on the “JBOF”.
As great as it may sound, this setup is not so easy to implement and use in practice.
There are a few drawbacks to using JBOF this way that we discovered while testing it, such as:
- network dependencе – JBOFs with NVMeOF requires a great network, often with RDMA support, expensive switch with RDMA support and 100% uptime of the network. So, if the network goes down for some reason, the storage system goes down as well and this might cause damage to the hosted data. Thus, it brings in an additional layer of troubles as well as some latency (but not much on RDMA NVMeOF).
- special skills required – JBOFs with NVMeOF require special technical expertise to be able to manage it. Almost each Linux administrator will be able to get NVMeOF working. However, making it work in a way that it doesn’t go down, does not break data or cause headache is another story with many variables.
So, using JBOF for our storage configuration sounded like a challenging venture to us initially.
Keeping in mind its deficiencies, we wanted to find a simpler solution, which is much more flexible, stable and cost-effective to maintain.
Luckily, the hardware setup we came up with finally allowed us to make the most of JBOF’s advantages.
Based on the following SuperMicro’s configuration – SuperMicro SSG-136R-N32JBF, we managed to build a true JBOF system, with no CPU and RAM included.
It has two PCI-e switches, fans, cables, power supplies, sleds and 32 bays. While most of 1U solutions provide an average of 10 NVMe slots, this solution provides a total of 32 NVMe slots.
As for the cost – it depends on the vendor, but you can find the configuration for about $4500.
However, it can’t be purchased empty. SuperMicro sells it with 8 cables, some AOC adapters (that’s а PCIe adapter on the host side) and a minimum of 8 NVMe SSDs.
The prices are rough, so keep in mind that they will vary. Also, as time goes by – flash storage prices become more affordable.
Here are the hardware specifications per storage cluster based on redundancy needs:
SSG-136R-N32JBF, SYS-2029TP-HTR (or WIO SuperServer if you prefer), AOC-SLG3-4X4P
The minimum hardware required for one storage cluster without full storage redundancy:
1x JBOF
2+ HyperVisors (1 is spare)
8x NVMe SSD
The minimum hardware required for one storage cluster with full storage redundancy:
2 JBOF’s
2+ HyperVisors (1 is spare)
16 NVMe SSD
The maximum hardware for one storage cluster with full storage redundancy:
2 JBOF’s
8 HyperVisors (1 is spare)
64 NVMe SSD
The vendor doesn’t usually have this setup in stock, so it takes a few weeks to get it shipped.
As mentioned earlier in this post, this SuperMicro configuration is supported by Windows and Linux only.
So if you want to run a more unconventional OS like FreeBSD or Solaris, then you won’t be able to use it.
Using such a JBOF system gives you the flexibility to build small storage clusters consisting of:
- 2 JBOFs in RAID1, full redundancy (even if you lose a whole JBOF), up to 8 HyperVisors;
- 1 JBOF and up to 8 HyperVisors in various RAID configurations (1/10/5/50/6/60);
To each storage cluster you can attach up to 8 HyperVisors.
We use 7 as operational and we keep 1 as spare in case any of the active HyperVisors fails.
Bringing up the spare HyperVisor in place of the operational HyperVisor is not difficult.
It requires one to zone the NVMe SSD drives from the faulty HyperVisor to the spare one (it takes about 2-4 minutes to do that), and then boot all VM’s.
As for storage redundancy, the RAID1 is the best option you can take advantage of.
RAID5 or even RAID6 are possible with a single JBOF.
Here is how we achieved redundancy on a storage level with RAID 1.
Each HyperVisor takes one drive from each JBOF and makes RAID1 of it.
In the event of an NVMe SSD failure – the HyperVisor will continue working using just one drive.
With good planning you should keep between 2 and 4 SSDs as spare on each JBOF (serving as spares for all connected hosts – up to 8).
In the event of an SSD failure the staff should be able to quickly replace the faulty SSD using one of the spares.
There will be absolutely no need for anyone to go to the Data Center and replace the SSD physically, which is really time-saving.
Also, NVMe SSDs are very fast, so they rebuild very fast accordingly.
To get a better understanding of the process, take a look at the following illustration:
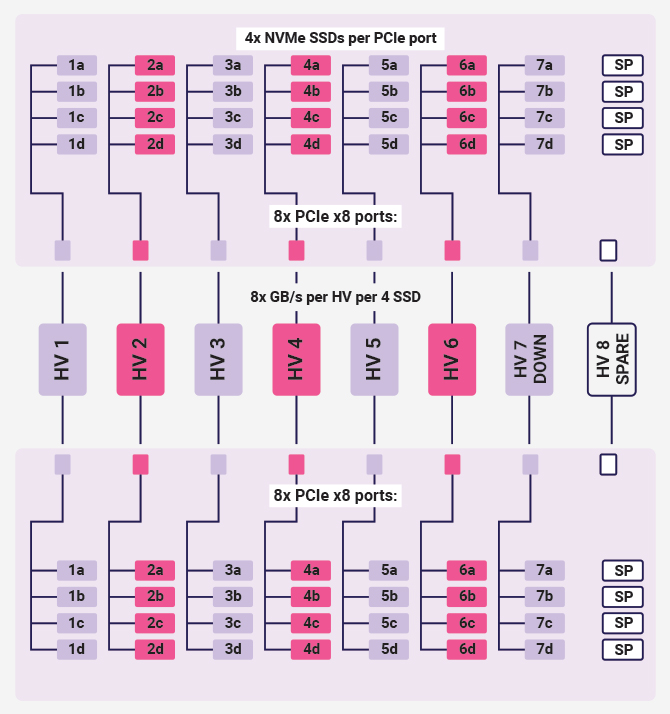
The following is a more detailed explanation of the diagram.
Depending on your data and needs, you can either make one RAID10 of all 8 SSDs per HV or make separate 4x RAID1 (1a with 1a, 2b with 2b and so on).
Having more RAID1’s gives you one advantage – the ability to move a certain RAID to another HV.
Let’s say you have data or service running on RAID 1a/1b – you can simply point those two disks for RAID 1a/1b to any other HV, including the spare HV.
This is done via zoning on the JBOF from IPMI, which also has CLI and can be put on script and automated.
Here’s a scenario where HV 7 fails and goes down. You try to bring it back, but no luck – it is dead.
What you need to do in this case is to point/zone all 8 SSD from HV 7 to HV 8 from the IPMI or CLI interface of the JBOF.
Here is how it will look like on the diagram:
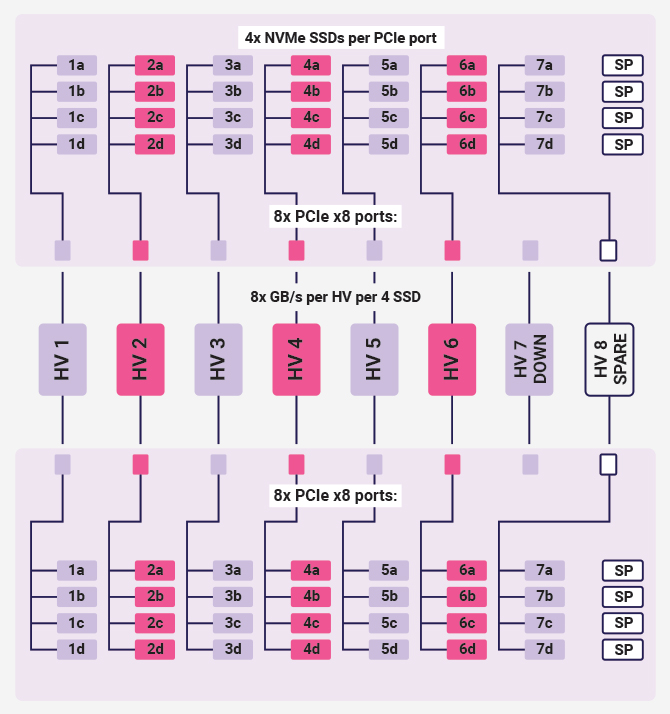
Then you can take down HV 7, fix it and return it as the spare HV in this cluster.
Just keep in mind that the spare HV should be at least as powerful and full of RAM as the most powerful one in the cluster.
Also, keep in mind that if you avail of less CPU or RAM, this might cause a bottleneck down the line.
This setup also gives you another great advantage – you could lose a whole JBOF and still have the system operating flawlessly.
So, if you need to move your storage over to another location and remain online – you can still perform it.
However, doing so is not recommended since that way you will have just a single copy of your data at hand.
Although it is not as critical as with Ceph or other similar distributed systems, you risk losing the final working copy of your data.
***
In our next post, we will go into more detail about the key differences between Ceph storage and the JBOF setup illustrated above i.e. the NVMe solution we found to be most suitable for our specific web hosting platform needs.
This will help you gain a better understanding of the custom hardware configuration that makes the perfect formula for lightning-fast storage performance across our web hosting system.

Leave a Reply